
Неполные данные? Шумные настройки? Давайте рассмотрим Робастные машины факторизации, недавнее шумозащитное дополнение в области контролируемого обучения.
Робастные машины факторизации, недавно предложенные на WWW’18, представляют собой семейство нелинейных классификаторов, которые учитывают любую потенциальную неполноту / шум данных. Они включают в себя принципы робастной оптимизации в очень выразительных машинах факторизации. В результате обученные модели демонстрируют высокую устойчивость к шуму.
В этом блоге делается попытка дать интуитивное представление о надежных машинах факторизации. Мы пропустим большую часть математических расчетов, доказательств и тому подобного.
Пожалуйста, обратитесь к исходной статье за строгим математическим объяснением. Этот блог прекрасно отражает мотивы, лежащие в основе статьи, и желаемую надежность в области прогнозирования ответов пользователей.
Давайте начнем с понимания двух ключевых слов:
1. Надежность,
2. Машины факторизации.
Надежность
Как выглядит базовый конвейер машинного обучения (ML)?
Возьмите какой-нибудь классификатор машинного обучения, введите в него данные и получите модель! Простой.

А как насчет ДАННЫХ?
Качество данных очень важно! Специалисты по анализу данных тратят много времени на получение «чистого набора данных». Но, как многие согласятся, существует лишь определенное количество операций по проектированию и очистке данных.

Что, если бы об этом позаботился классификатор ❤?
Надежные классификаторы по сравнению со стандартными классификаторами?
Классификаторы различаются обработкой обучающих данных и, следовательно, постановкой задач оптимизации.
Стандартные классификаторы:
- предполагается, что данные точно известны.
- сформулированы как проблема минимизации потерь w.r.t. вектор веса (w) изучается
- представлен на рис. 1 (а).
Надежные классификаторы:
- предполагают неопределенность, связанную с каждой точкой данных. Понятие детерминированной неопределенности, основанной на множестве U. См. Уравнение. 1. Это позволяет точке данных теперь существовать где угодно в гипер-прямоугольном многообразии. См. Рис. 1.
- оформлена как проблема Minimax, минимизация потерь w.r.t. вектор веса (w), а также максимизация w.r.t. неопределенность (U).
- представлена на рис. 1 (б).
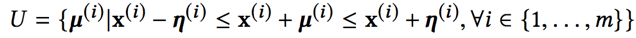
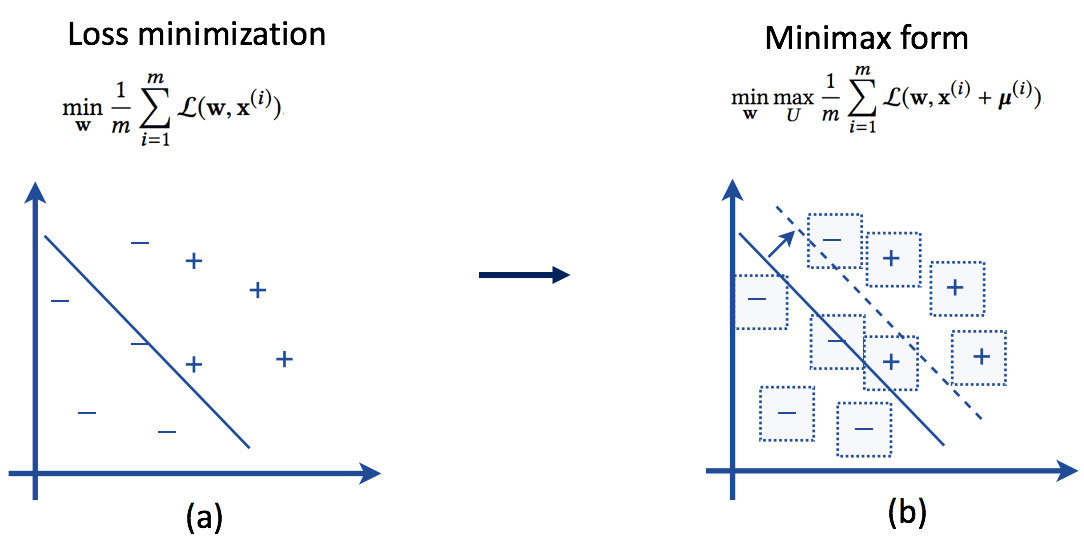
Вкратце, надежная оптимизация направлена на изучение классификатора, который остается выполнимым и близким к оптимальному при реализации неопределенности наихудшего случая.
Машины факторизации
Возьмем сценарий классификации.
Для задачи прогнозирования покупок с двумя функциями (item_category и device), если мы знаем, что категория "одежда" часто покупается на "мобильных" , а не на "рабочем столе", как нам фиксировать такие взаимодействия функций? Как модель отражает важность взаимодействия функций, например 'device = mobile and category = clothing', над рассмотрением только отдельных функций? Сама по себе линейная модель не имеет значения. хватит.
Машины факторизации (FM), предложенные Штеффеном Рендлом, представляют собой семейство нелинейных классификаторов, предназначенных для фиксации взаимодействий функций в скрытом пространстве. То есть для каждого объекта изучается p -мерный вектор, в результате чего получается матрица весовых коэффициентов d x p, где d оригинальный нет. функций. Сходство между двумя признаками затем определяется скалярным произведением этих скрытых векторов, например. как показано на рис. 2, ч / б характеристики силы взаимодействия j и k будут вычисляться как скалярное произведение по следующим двум векторам: скрытый вектор для характеристики j ( v_j) и скрытый вектор для функции k ( v _k).

Надежные машины факторизации
Теперь, когда мы выработали некоторую интуицию о машинах устойчивости и факторизации, пришло время раскрыть ключевые аспекты статьи под названием Надежные машины факторизации для прогнозирования реакции пользователя.
Статья мотивирована использованием зашумленных и неполных данных, доступных в задаче Прогнозирование реакции пользователя. Загляните в наш блог, в котором описывается потребность в надежности домена.
Ключевая идея - расширить машины факторизации, используя принципы робастной оптимизации. Результирующая минимаксная формулировка затем преобразуется в чистую задачу минимизации путем получения верхних границ потерь относительно. матрица неопределенности U.
В статье предлагаются два новых алгоритма:
- Робастные машины факторизации (RFM).
- Надежные машины факторизации с учетом поля (RFFM).
Обширные эксперименты с крупномасштабными наборами данных в реальном мире дают представление о производительности и масштабируемости предложенных алгоритмов.
Обнадеживающие результаты:
- Значительное снижение (с 4,45% до 38,65%) логопотерь в настройках с шумом.
- Небольшое снижение производительности (от -0,24% до -1,1%) в режиме без шума.
Распределенная реализация предложенных алгоритмов на основе Spark с открытым исходным кодом доступна здесь. Оценка RFM и RFFM по широкому кругу сценариев классификации - интересная область для исследования.
RFM и RFFM - это независимые от предметной области формулировки, применимые в любой области с зашумленными / неполными данными.
Выдвигая на первый план надежность
С увеличением шума во входных сигналах важно разработать классификаторы, учитывающие эту неопределенность. RFM и RFFM - шаг в этом направлении. Включение устойчивости в древовидные ансамбли и глубокие нейронные сети - многообещающая область исследования.